無料のデータ分析サービス Mi-Analyzer のサーバー構成を解説します!
Mi-Analyzerを4月23日にリリースしました!
--- 2021/11/7 追記 ---
すみませんが、Mi-Analyzerのサービス提供は終了しました。 多少お時間をいただく可能性が高いですが、今後、OSSとして一部公開を目指しています。
--- 追記終わり ---
Mi-Analyzerはスプレッドシート形式のデータを簡単に分析できる、無料のデータ分析サービスです。
現状ではコードは公開していませんが、今回はサーバー構成について、利用技術や導入理由などを解説しようと思います。
使用技術とサーバー構成
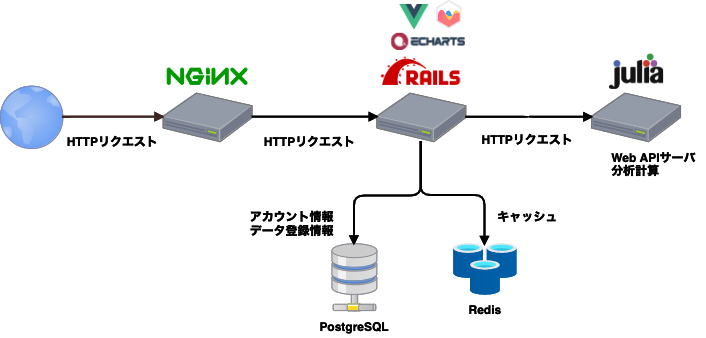
Mi-Analyzerでは主に、Ruby on Rails と Julia を利用しています。
Ruby on Railsでは、「アカウント管理」「永続化するデータの管理」「ブラウザへのレスポンスの返却」を行っており、フロントエンドサーバーとして機能しています。
一方で、Juliaでは、「データの分析」を行っており、バックエンドサーバーとして機能しています。
また、Nginxでは静的ページの配信や、細かいアクセス制御を行っています。
フロントエンドサーバー(Ruby on Rails)
フロントエンドサーバーは、一般的なRuby on RailsとしてのWebサーバー機能を利用しています。そのため、そこまで面白みのある部分は少ないのですが、以下に使用している技術を列挙します。
- チャート表示: Chart.js、Apache ECharts、Vue.js
- アカウント管理: Devise、Google OAuth 2.0
- スプレッドシート読み込み: Google APIs
- その他: Interactor、Draper
フロントエンドサーバーの技術選定ですが、Ruby on RailsにしたのはWebサーバー構築として最も慣れていたため、という理由です。Pythonなどであれば、Webサーバーから分析までを1台のサーバーで構築できるかと思いますが、今回はあえて分離する構成を取りました。こちらの理由については後ほど説明します。
チャート表示(Chart.js、Apache ECharts、Vue.js)
Chart.js、Apache EChartsはチャート表示に利用しています。
基本的にはChart.jsを利用しているのですが、一部でEChartsを利用しています。
Chart.jsは一般的なチャートをHTMLで表示する際にかなり便利なJavaScriptライブラリです。利用についてもシンプルで、Web上の文献も多いのが特徴です。
Chart.jsを導入している状況で、EChartsを導入した理由としては、ツリー表示の導入があります。
Mi-Analyzerでは、各項目の類似度合いをクラスタリング分析するために、階層クラスタリング分析を提供しています。こちらの結果表示にツリー形式の表示を行いたかったのですが、Chart.jsでは達成できませんでした。そこで、多様なチャート表示をサポートしているEChartsを導入しました。
単一のライブラリで対応するほうが基本的には良いのですが、すでにChart.jsで大部分を実装していた点、また特定の分析のみ複数ライブラリの利用は許容として、既存のChart.jsを置き換えず、追加でEChartsを導入しました。
Vue.jsは、これらの各チャート表示をコンポーネント化するのに利用しています。
SPA表示はRuby on Railsで実装するのであれば、コスト的にそれほど見合わないだろうということで見送りました。今後、Ruby on Rails以外でWebサーバーを開発する際には検討してみたいなと思っています。
アカウント管理、スプレッドシート読み込み: Devise、Google OAuth 2.0、Google APIs
アカウント管理はDevise(gem)、サインインにはGoogle OAuth 2.0を用いています。
ここはログイン周りの開発コストを抑え、また自サービスでユーザーのパスワード管理を受け持つリスクを下げる目的でこのようにしています。
Google OAuth 2.0 を選んだのは、Googleスプレッドシート読み込みの機能を提供するためです。Googleスプレッドシートから読み込むことができれば、データ更新に対して簡単にMi-Analyzer側でもデータの更新を提供することができます。そこで、アカウント自体を最初からGoogleアカウントで提供しています。
ちなみにGoogleのユーザーのデータにアクセスするためには、Googleの承認を受ける必要があります。実際のホームページやプライバシーポリシー、必要な各権限がどこで利用されているかというのを動画で提出する必要などがあり、意外と手間がかかり、スムーズに行っても1週間ほどはかかります。もし、同じようなGoogle Driveへのアクセス等が必要になるサービスを不特定多数に提供することを検討している人は、このあたりが最後にあることを把握しておくとよいかと思います。
その他
Ruby on Rails での開発にInteractor、Draperを導入しました。
Interactorは、1つのことを行うだけのオブジェクト(Interactor)を実装するための機能を提供するgemです。おもにバックエンドサーバーへのアクセスやGoogleスプレッドシート取得部分を実装するのに利用しています。
Draperは、Model、Viewの間にDecoratorを作成し、表示用のロジックをModelから分離することができるgemです。Mi-Analyzerではチャート表示などもあり、ModelからViewへの受け渡しが複雑なのですがそこを分離できたため、Modelをシンプルに保つことができました。
上記については以前簡単にまとめた記事を書いたため、こちらを参照してください。
バックエンドサーバー(Julia)
データ分析を行うバックエンドサーバーは、Juliaを採用しました。データ分析ではPythonが有名ですが、JuliaがPythonなどの資産を利用しつつ、数学的な計算を行うのに向いているということで、技術的チャレンジも兼ねて採用しています。
バックエンドサーバーもWebサーバーですが、Web APIサーバーとして、フロントエンドサーバーからのみリクエストをJSON形式で受け付けて、データ分析結果をJSONで返すようにしています。
そのため、バックエンドサーバーでは、DB等の永続化データへのアクセスはありません。
Juliaでは、Webフレームワーク(Ginie)も存在しており、こちらの導入の検討も行いました。ただ、今回は非常にシンプルなWeb APIサーバーであり、あえて学習コストやハマリポイントを調査しつつ導入する理由はないと判断しました。
上記のような判断もあり、シンプルなJSON形式でやり取りするようにし、Julia標準のHTTPライブラリを利用して構築しました。このサーバー構築の簡易版構成については、別記事で書いています。とくにサーバーとして利用する場合、Channel等での並行処理化とPackageCompilerによる事前のパッケージコンパイルは必須になりそうです。
データ分析の実装
Juliaは前述のように、Pythonなどの資産を利用することができ、Juliaで高品質なライブラリがある場合はそちらを、機能的に足りない場合はPythonのライブラリを利用しました。
そのため、Juliaですが、scikit-learnやPyClusteringを利用しています。これは多少注意点はありますが、PyCallを使うことでかなり簡単にJuliaから呼び出すことができます。
一方で、JuliaからPythonの呼び出しを行う際にPyCallを利用しているのですが、どうやらスレッドセーフではないらしく、色々試したのですがマルチスレッドで呼び出しをするとsegmentation faultで落ちるため、Pythonの資産を利用する際にはシングルスレッドで並行処理をさせるようにしています。
サーバー構成の理由
サーバー構成の理由ですが、結果を表示するフロントエンドサーバーと、データ分析を行うバックエンドサーバーを分けた構成というのを試してみたいと前々から思っていたので、この構成を採用してみました。ちょうどJuliaにチャレンジしてみたいという気持ちもあり、バックエンドにJulia、フロントエンドは慣れているRailsとすることで開発の難易度を調整しました。
おわりに
あいだで開発が停滞した期間もありましたが、無事Mi-Analyzerをリリースすることができました。
実際にサービス開始できるまでの開発は、上記以外にもLPや利用規約・プライバシーポリシーなど技術以外にも色々と準備するものがあったのですが、そちらは書く機会があれば別途書かせてもらおうと思います。
色々あってようやくサービス開始したので、ぜひ皆さんにも活用してもらえれば幸いです!