複数のシステムからアクセスできるデータ基盤のような環境を作成しようとした場合、自前でのAPIの構築や認証/認可などの仕組みを整える必要があります。
一方で、データ基盤としては、最初はそこまでパフォーマンスチューニングや特別な機能を必要としていないため、大きなコストをかけて構築するよりは素早く本番レベルで検証できるほうがよいという場合もあります。
このような場合に利用できそうな、DBに接続するだけで自動的にGraphQLサーバーを建てられるHasuraというOSSがあるので、試してみました。
Hasuraとは
すでに書きましたが、既存のデータベースに対して接続させることで、簡単にGraphQLサーバーを構築できるOSSです。
サポートされるデータベース
現在サポートされているデータベースはPostgreSQLをはじめ、MySQLやSQL Server、Amazon AuroraといったRDBや、Google BigQuery、Amazon Athena、Snowflake、MongoDBなどもサポートされています。
サポートされる全データベースは、以下にリストアップされています。
Instant GraphQL APIs & REST APIs on Databases
GraphQLのページネーションや集計クエリのサポート
GraphQLサーバーを構築する際に難しいとされている、ページネーション、集計クエリなども自動的に生成されるため、自前で構築するよりも格段に早く始めることができます。
参考(PostgreSQLの例):Postgres: Paginate query results | Hasura GraphQL Docs
認証、認可のサポート
認証、認可についてもサポートされています。
外部のAuth0などと組み合わせることで、認証したり、ロールベースでテーブルやレコードへのアクセス制限ができます。
認証プロバイダーから取得したJWTに含まれる情報をもとに、アクセスできるレコードを絞り込むといったこともできます。
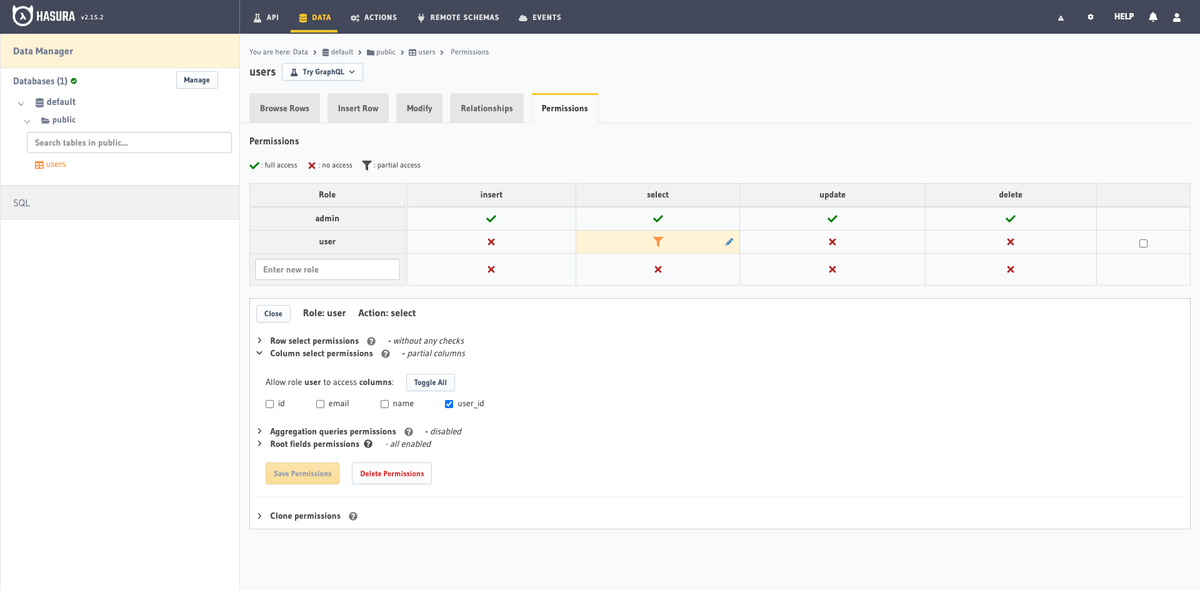
Authentication & Authorization | Hasura GraphQL Docs
実際にローカルで試してみる
以下のドキュメントに docker compose で起動するための手順が記載されているので、そのまま実行してみます。
Quickstart with Docker | Hasura GraphQL Docs
起動したら、http://localhost:8080/console にアクセスします。

まずは、データベースに接続するため、ヘッダーメニューのDataのページを開き、Connect Databaseでデータベースに接続します(ドキュメントのdocker-compose.yamlを利用している場合、PostgreSQLサーバーが起動しています)。

接続設定をしたら、ヘッダーメニューからAPIのページに戻り、GraphQLのクエリを記載して実行するとアクセスできます。

おそらく、初回はテーブルなどが存在していないので、試す際には、Dataのページで「Create Table」や作成したテーブルを選択してから「Insert Row」などでレコードの追加をしてから試してください。
まとめ
気になっていた、Hasuraを試してみました。
サポートされているデータベース自体も多く、Webで調べた限り、本番環境で利用している事例もそれなりにあるようです。
ローカルで試すくらいのレベルだと今回の記事のように非常に簡単に試せるので、社内向けから検証してみるなどは比較的低コストでできそうですね。